From Sound to Sight:
Towards AI-authored Music Videos
Abstract
Conventional music visualisation systems rely on handcrafted ad hoc transformations of shapes and colours that offer only limited expressiveness. We propose two novel pipelines for automatically generating music videos from any user-specified, vocal or instrumental song using off-the-shelf deep learning models. Inspired by the manual workflows of music video producers, we experiment on how well latent feature-based techniques can analyse audio to detect musical qualities, such as emotional cues and instrumental patterns, and distil them into textual scene descriptions using a language model. Next, we employ a generative model to produce the corresponding video clips. To assess the generated videos, we identify several critical aspects and design and conduct a preliminary user evaluation that demonstrates storytelling potential, visual coherency and emotional alignment with the music. Our findings underscore the potential of latent feature techniques and deep generative models to expand music visualisation beyond traditional approaches.
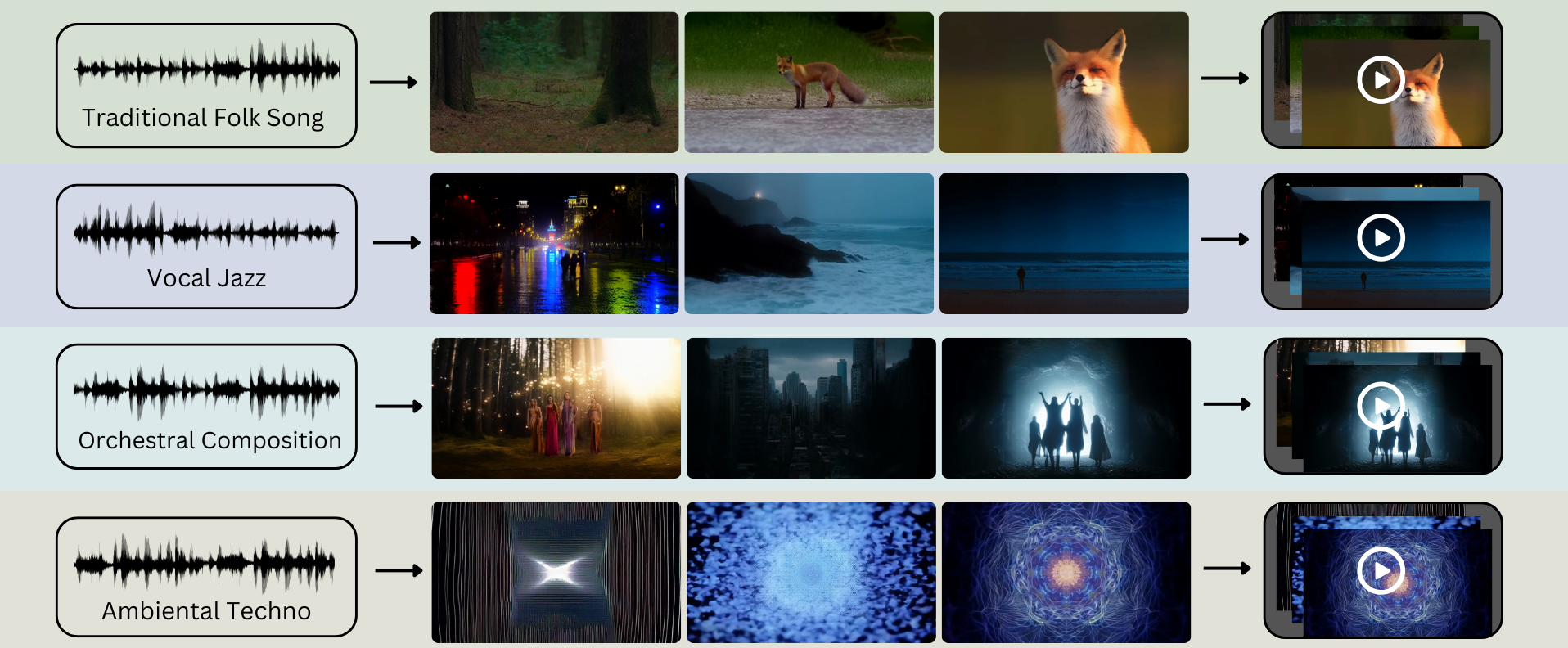
Methodology
We propose two distinct pipelines for generating music videos from audio. Both pipelines segment the input song, perform audio analysis to generate a script, create video clips from the script using text-to-video models, and finally assemble the clips into a final video.
Pipeline 1: CLAP-based Approach
This pipeline uses Contrastive Language-Audio Pre-training (CLAP) to extract semantic labels describing the audio's style, content, and emotion. These labels, which capture both segment-specific details and the overall track's mood, are fed into a Large Language Model (LLM). The LLM then generates a coherent video script with concise scene descriptions, which are used to prompt a text-to-video model.
Pipeline 2: LALM-based Approach
This alternative approach leverages a Large Audio Language Model (LALM) to generate a narrative concept directly from the raw audio. The LALM is prompted to create a short story that thematically and emotionally aligns with the song. This story is then broken down into segment-aligned scene descriptions, either by the LALM itself or a reasoning LLM, which are then used to generate the video clips. This method aims for a more integrated and creative interpretation of the music.

Overview of the two proposed music video generation pipelines.
Results
We conducted a user study to evaluate the generated videos. A quantitative evaluation with five participants showed that the CLAP-based pipeline was rated slightly higher on average across dimensions like Storytelling, Visual Impression, and Emotional Consistency. However, the small sample size means these results are exploratory.
A qualitative evaluation with a non-expert and a professional videographer revealed that while the AI-generated narrative concepts were often fitting, the final videos suffered from a lack of visual and narrative consistency. Characters frequently changed appearance, and the visual style was disjointed between scenes, which broke the narrative thread and emotional investment.
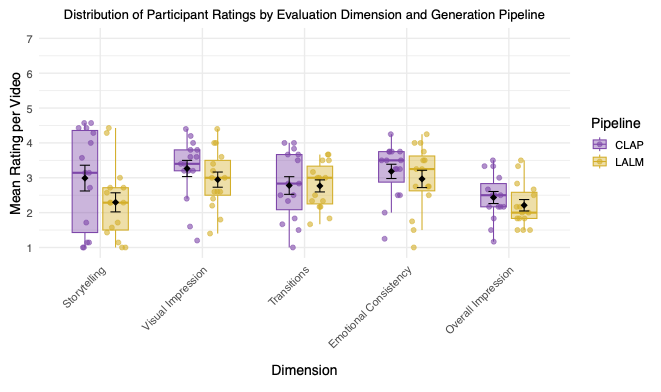
Participant Ratings by Dimension and Generation Pipeline.
Poster (ICCV 2025)
BibTeX
@InProceedings{Vitasovic_2025_ICCV,
author = {Vitasovic, Leo and Gra{\ss}hof, Stella and Kloft, Agnes Mercedes and Lehtola, Ville V. and Cunneen, Martin and Starostka, Justyna and Mcgarry, Glenn and Li, Kun and Brandt, Sami Sebastian},
title = {From Sound to Sight: Towards AI-authored Music Videos},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
month = {October},
year = {2025},
pages = {3792-3802}
}